
Machine-generated hypotheses
We did some fun experiments by automating hypothesis pre-registrations for empirical studies about US-American politics. Specifically, we fine-tuned models to predict how different attitudes are going to correlate in the US public. The models performed quite well when comparing their hypotheses to the actual attitude corrlations (see image below).
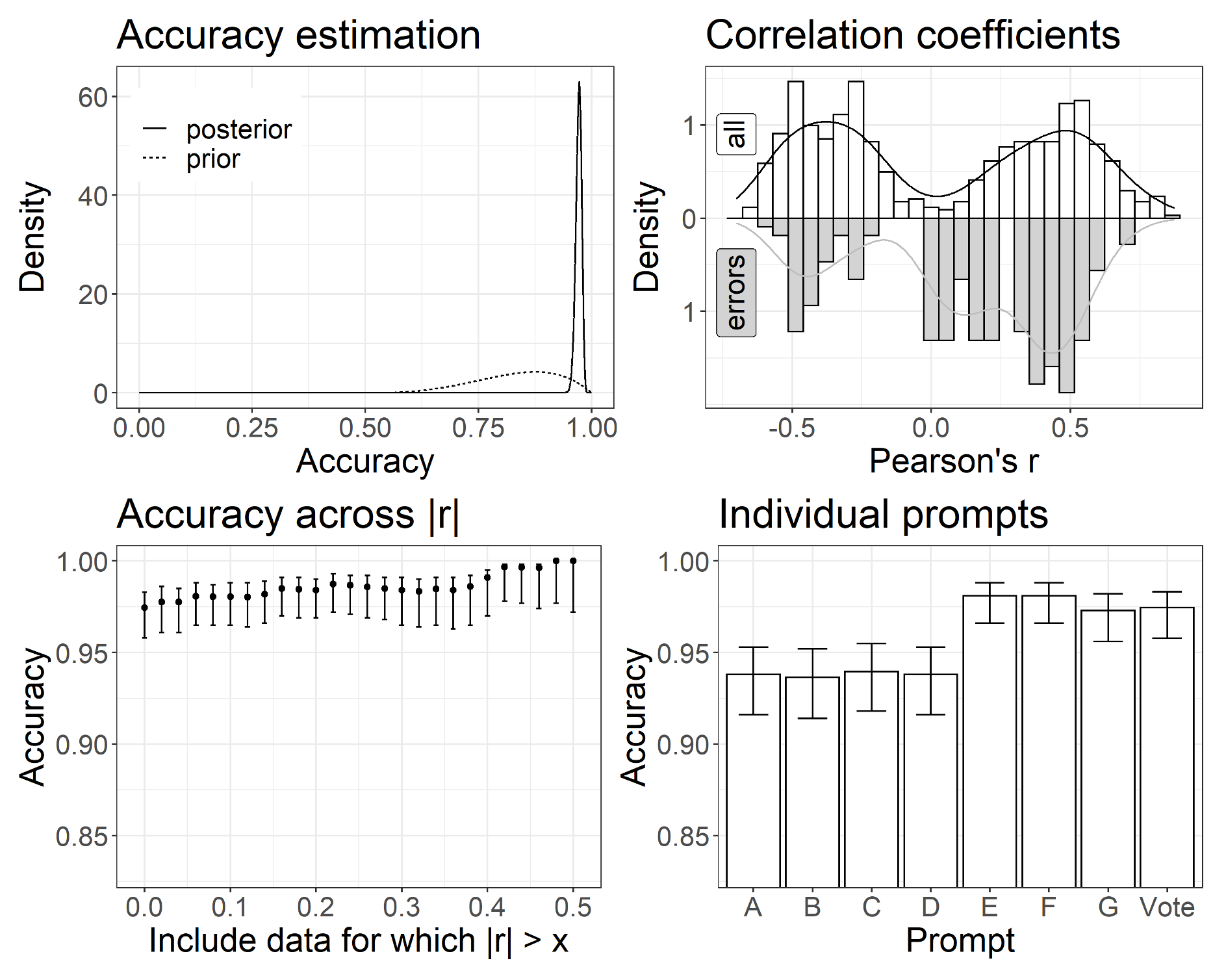 Top left: Estimated accuracy of GPT-3. Top right: Distribution of empirical correlation coefficients (i.e., prediction targets) and mispredicted coefficients of individual prompts. Bottom left: Prediction accuracies when excluding small correlation coefficients. Bottom right: Isolated performances of prompts. Whiskers signify 95% credible intervals. The accuracy prior followed a beta distribution from 0.5 to 1 with a = 4 and b = 2.
Top left: Estimated accuracy of GPT-3. Top right: Distribution of empirical correlation coefficients (i.e., prediction targets) and mispredicted coefficients of individual prompts. Bottom left: Prediction accuracies when excluding small correlation coefficients. Bottom right: Isolated performances of prompts. Whiskers signify 95% credible intervals. The accuracy prior followed a beta distribution from 0.5 to 1 with a = 4 and b = 2.
Maybe machines are finally going to take over the behavioral sciences as well. I could concentrate on getting yolked! If you are interested in the work here is the abstract (paper is currently under review).
We test whether GPT-3 can accurately predict study outcomes in the social sciences. Ground truth outcomes were obtained by surveying 600 adult US citizens about their political attitudes. GPT-3 was prompted to predict the direction of the empirical interattitude correlations. Machine-generated hypotheses were accurate in 78% (zeroshot), 94% (five-shot and chained prompting), and 97% (extensive finetuning) of cases. Positive and negative correlations were balanced in the ground truth data. These results encourage the development of more general hypothesis engines. Moreover, they highlight the importance of addressing the numerous ethical and philosophical challenges that arise with hypothesis automation. While hypothesis engines are likely to compete successfully with human researchers in terms of empirical accuracy, they have drawbacks that preclude full automations for the foreseeable future.