
What books do I like?
Despite keeping track of my own book ratings and writing short reviews for every book that I read (including DNFs), I find it difficult to pinpoint my own literary preferences.
Like many readers, I don’t thinkt that I have a preferred niche, which would make the process of finding enjoyable reads much easier.
With about a hundred book ratings in my spreadsheet, I started to look for statistical patterns. Specifically, I built an AI-enhanced pipeline to discover regularities in my reading enjoyment.
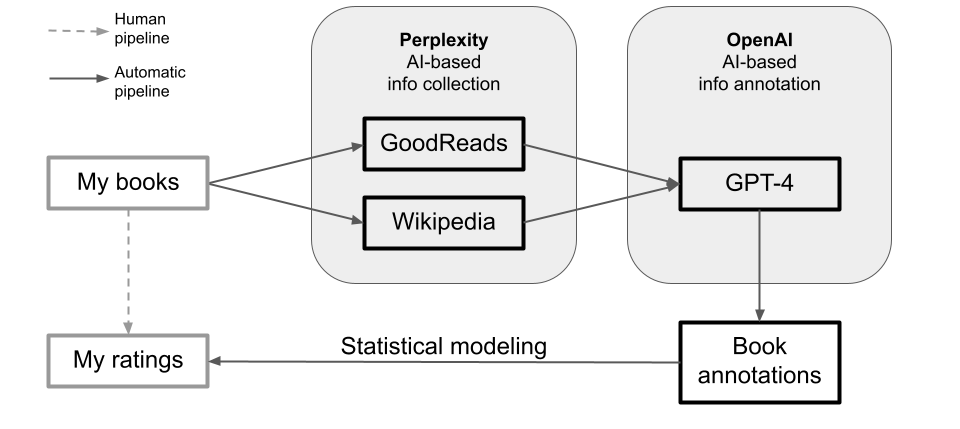 The ISAAC pipeline retrieves book-relevant information from the internet, feeds this information into an LLM prompt which outputs binary labels for a range of predetermined book dimensions (e.g., target groups, themes, attributes of main characters).
The ISAAC pipeline retrieves book-relevant information from the internet, feeds this information into an LLM prompt which outputs binary labels for a range of predetermined book dimensions (e.g., target groups, themes, attributes of main characters).
The AI pipeline worked very well, and allowed me to examine how individual book characteristics predict my reading enjoyment. Unfortunately, most effects were rather small and uncertainty remained large. This was to be expected, as many book characteristics have only appeared a handfull of times in the books I have read/rated.
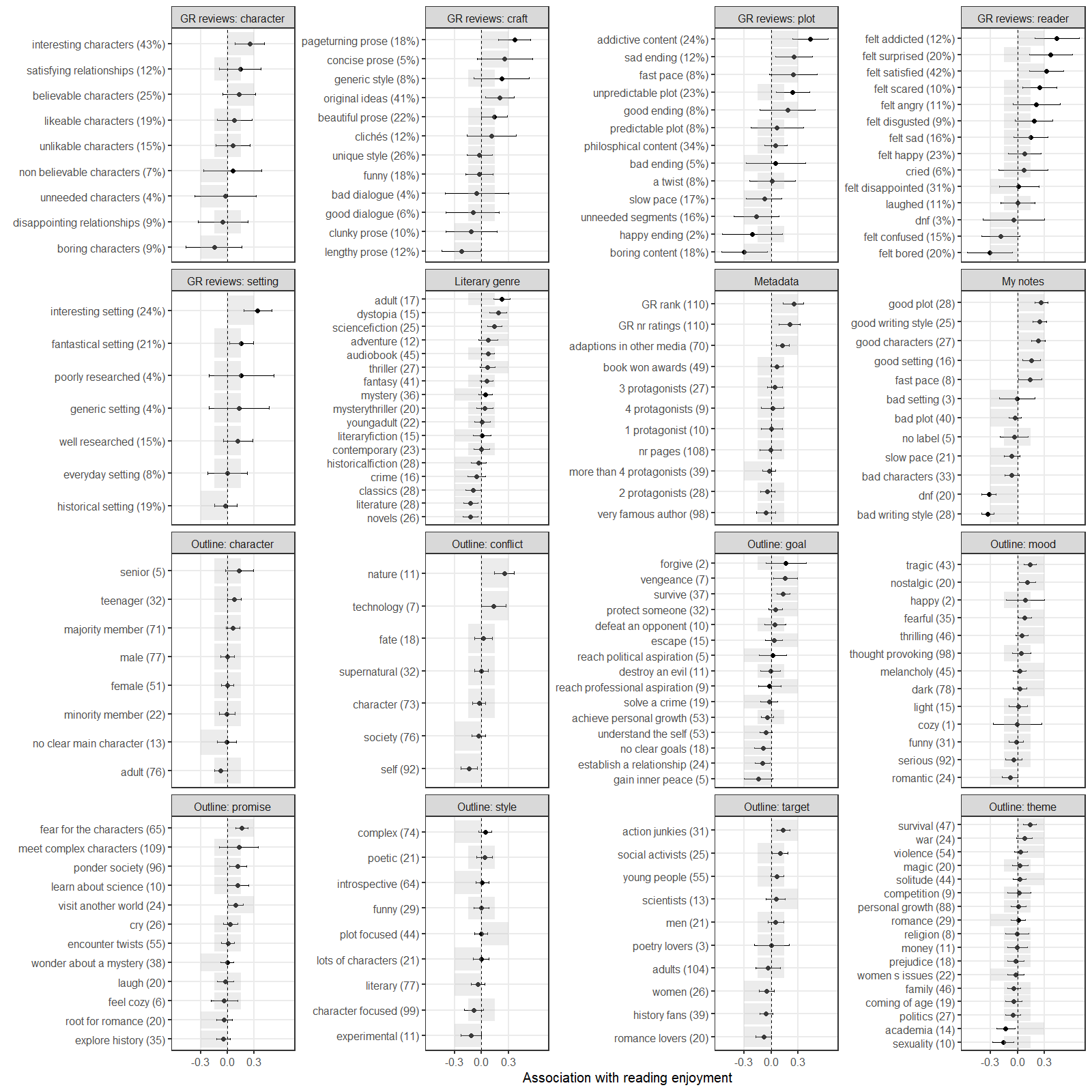 The point estimates show correlations between book annotations and reading enjoyment. Gray bands indicate how the first author judged his own literary preferences based purely on introspection. Number of books is given in parentheses. Error bars are 80% credible intervals from Bayesian simple linear regressions of reading enjoyment on annotations, with Beta(1,1) priors scaled to [-0.5, 0.5] for the focal coefficients and a standardized outcome variable.
The point estimates show correlations between book annotations and reading enjoyment. Gray bands indicate how the first author judged his own literary preferences based purely on introspection. Number of books is given in parentheses. Error bars are 80% credible intervals from Bayesian simple linear regressions of reading enjoyment on annotations, with Beta(1,1) priors scaled to [-0.5, 0.5] for the focal coefficients and a standardized outcome variable.
I got some interesting nudges from this analysis (my enjoyment correlates .29 with the mainstream, and maybe I don’t dislike the crime genres as much as I had thought). Naturally, I followed up by training a personal book recommendation model.
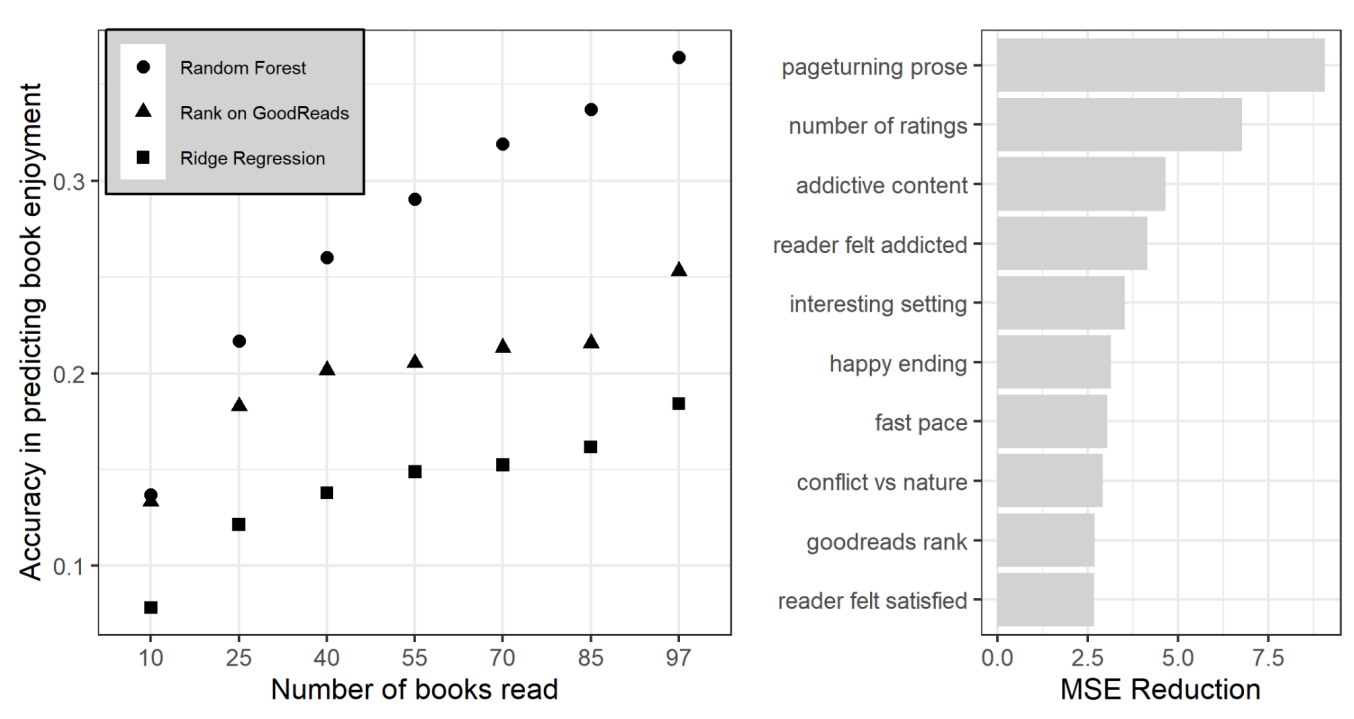 Left: the Pearson correlation between predicted book rating and actual book rating. Each sample size (X axis) was drawn 30 times via bootstrap sampling and the average model performance is plotted. Right: The top 10 predictors within the full-sample random forest model, ranked according to their error reduction.
Left: the Pearson correlation between predicted book rating and actual book rating. Each sample size (X axis) was drawn 30 times via bootstrap sampling and the average model performance is plotted. Right: The top 10 predictors within the full-sample random forest model, ranked according to their error reduction.
It appears like the annotation-based recommendation system works reasonably well, gets better as I continue reading, and definitely beats the baseline heuristics of ranking books based on average review scores or genres.
If you are interested in the full paper (co-authored by Erdem O. Meral), please check it out here.